常见问题
探针安装成功,为什么控制台上仍无监控数据?
正常情况下,当您的应用有请求访问后,约5分钟左右,即可在控制台中查看数据。如果没有数据,可能是以下原因导致的:
探针超量
查看方法:在左侧导航栏中依次单击管理>配置>Agent管理>Agent管理中查看探针运行状态。 解决方法:禁用掉暂不关注的应用的探针或者购买探针。
没有数据访问
解决方法:多次访问嵌入探针的应用后,稍等1分钟左右再在页面中查看。
服务器间的时间或时区不一致
解决方法:更正探针所在服务器的时间,与DC时间一致;若是SaaS用户,需将探针所在服务器时间更新至当前时间。
配置错误
解决方法:确认tingyun.properties配置文件中的license_key和collector.addresses配置项的值是否完整或者有多余字符。
网络不通
查看方法:查看/path/to/tingyun/logs/tingyun_agent.log
现象如下图所示:
解决方法:检查网络状态,保证端口通信正常。
Tomcat没有缓存目录temp,导致探针启动失败
现象:Tomcat加载探针启动后,/path/to/tingyun/logs/目录下未生成tingyun_agent.log。
解决办法:在Tomcat根目录下创建temp目录即可。
安装探针后,应用启动报错怎么办?
- 问题现象1:
日志中报错如下:
Error opening zip file or JAR manifest missing : /home/apache-tomcat-8.0.36/tingyunn/tingyun-agent-java.jar
Error occurred during initialization of VM
agent library failed to init: instrument
原因:
找不到指定路径下的tingyun-agent-java.jar或者tingyun-agent-java.jar文件不完整导致启动失败。
解决方法:
校正探针的绝对路径或查看探针的md5,保证探针解压后的完整性。
- 问题现象2:
日志中报错如下:
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "Tingyun Agent Shutdown" java.lang.OutOfMemoryError: GC overhead limit exceeded
原因:
内存不足。
解决方法:
增加内存上限,具体数值需联系技术人员。
- 问题现象3:
日志中报错如下:
java.lang.VerifyError:null
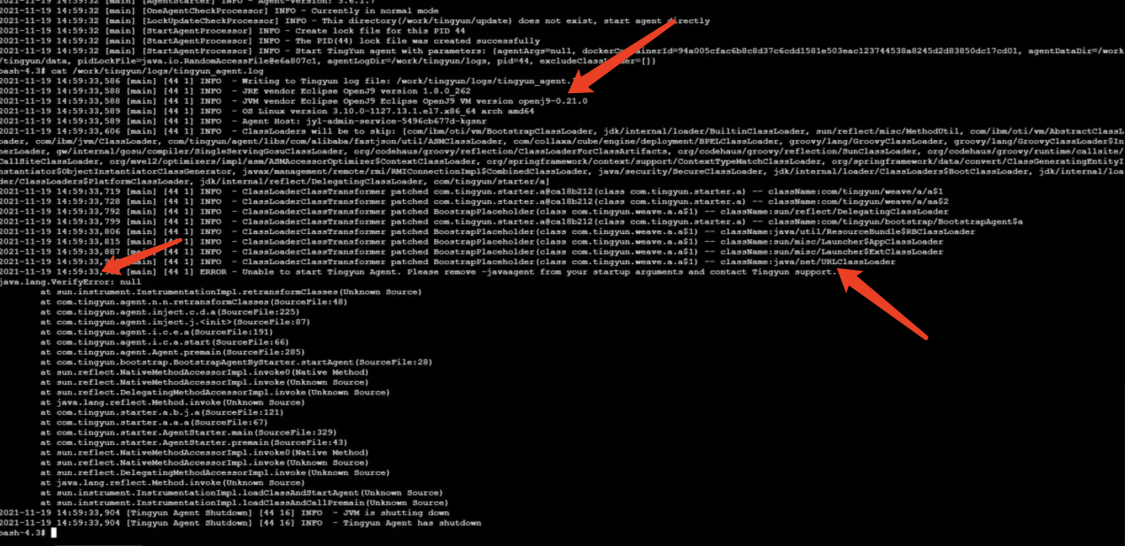
原因:
直接原因是java/net/URLClassLoader嵌码后,校验失败。根因是客户使用的JDK是OpenJ9所致。
解决方法:
探针配置如下:
class_transformer.classloader_delegation_excludes=java/net/URLClassLoader
安装探针后,没有生成logs目录
现象:Java探针部署完后,执行ps -ef |grep tingyun,已经有tingyun应用进程了,但是tingyun目录下没有生成logs目录。
原因:
可能有以下三种情况:
有其他厂商的探针,可以通过
ps -ef |grep agent确认。 如果有,需要在友商目录下执行uninstall命令。直接使用killall命令杀掉友商的进程,是无效的。tingyun目录没有权限,至少需要给755的权限。
chmod -R 755 ./tingyuntingyun.properties里应用名是全数字(不允许以数字开头);tingyun.properties里有乱码;tingyun.properties里有错别字,例如true错写成ture,false错写成flase。
数据库连接池没有数据如何解决?
确认数据库连接池版本是否在支持范围内。具体请参见支持列表。
确认数据库的JDBC URL是否在支持范围内。具体请咨询基调听云TAM人员。
控制台事务追踪详情中有数据库连接池数据,但连接池中没有数据。
问题原因:数据库连接池注册信息入库失败,探针只会上报一次注册信息。
解决方法:重启探针。
没有访问数据库连接池。
解决方法:多次访问调用数据库连接池的接口,稍等1~2分钟,再次查看连接池数据。
如何缩短应用加载探针后的启动时间?
现象:应用加载探针后,启动时间比不带探针时延长了几十秒或几分钟。
解决方法:
第一次加载探针启动后,在报表端查看应用,默认应用所在业务系统为default。
在左侧导航栏中依次选择应用与微服务>应用,业务系统选择default→选择对应的应用→选择对应的实例→选择环境信息页签→选择Instrument Detail。
查看探针插件的Status状态,把除了Inspected之外的插件都禁用掉。
在探针配置文件tingyun.properties内,添加Skipped的Extension Name,在探针下次启动时便不会加载这些plugin,添加规则为class_transformer.组件名称.enabled=false。
配置完成后,保存并重启应用即可。
探针运行后,发生应用内存使用率骤增怎么办?
当发现应用内存溢出或长时间使用内存很高的情况下,通过内存dump分析原因。
1、取内存dump, 把进程内存使用情况dump到文件中。
jmap -dump:format=b,file=wx.hprof <pid>
2、使用mat打开dump文件。
当com.tingyun.agent.inject.c.j的大小超过200M时,探针大概率有问题。
当tingyun的对象占比超过20%时,探针大概率有问题。
3、找到引用对象。单击右键,选择Path To GC Roots > exclude all plantom/weak/soft etc. References。
说明:exclude all plantom/weak/soft etc. References:排除了虚引用、弱引用、以及软引用,剩下的就是强引用。从GC上说,除了强引用外,其他的引用在JVM需要的情况下是都可以被GC掉的,如果一个对象始终无法被GC,就是因为强引用的存在,从而导致在GC的过程中一直得不到回收,因此就内存溢出了。
找到强引用对象,由研发分析。
探针运行后,报表数据不准确如何解决?
业务系统/应用/事务的错误数与错误分析的错误数不一致。
原因:错误分析的错误数为事务的错误数,查看是否有服务接口发生错误。
错误分析页面中,事务错误趋势的错误数与事务错误列表的数据不一致。
原因:两个图表查询的表不一致,可能入库时间不一致导致数据不一致。
错误分析页面中,事务错误类型分解的错误数与事务错误列表的数据不一致。
原因:
事务错误列表限制1000条事务。
事务错误列表会过滤action_id为0的数据。
新旧版错误分析的数据不一致。
原因:新版错误分析和旧版错误分析的逻辑不一致,新版错误分析不统计后台任务发生的错误/异常。
错误分析页面中,错误追踪列表无数据。
原因:
Elasticsearch入库或查询报错。
Exception Messages含特殊符号导致查询不到对应的数据(V3.6.2.0解决)。
Database有错误次数,错误列表显示无数据。
原因:错误次数统计该组件发生的所有的错误数,错误列表只显示Database Exception类型的错误。
追踪详情中,异常数量与异常页签中的数据不一致。
原因:异常数量统计的是入口事务/服务接口的异常数量,异常页签显示的是入口及下级调用发生的异常。
App/Web跳转到应用与微服务的追踪详情提示“查询不到数据或结果不止一条”。
原因:
查询时间段无追踪数据。
多条相同trace_guid的数据。
事务列表中,单个应用下有事务,应用选择“全部”搜索不到该事务。
原因:事务列表按响应时间倒排序限制500条数据,该事务在500条数据外导致搜索不到。
客户业务有连接池,报表追踪详情未显示连接池数据。
原因:连接池的注册信息未上传。
配置数据项时,找不到对应的class信息。
原因:class信息未入库,写库失败。
事务追踪列表有数据,进入追踪详情提示查不到数据或报错。
原因:NBFS查询或解析报错。
探针部署后,控制台上一直看不到应用
排查思路:
1、查看探针日志是否生成。
/path/to/tingyun/logs目录下应该生成tingyun_starter.log(启动日志)和tingyun_agent.log(探针日志)两个日志文件。
2、若只有tingyun_starter.log日志生成,则代表启动时存在问题,需要根据日志内容查看具体错误原因。
3、若两个日志均生成,则查看tingyun_agent.log,需要根据日志内容查看具体错误原因。
- 问题现象1:
只有tingyun_starter.log日志生成,日志内容如下:
原因:
Tomcat没有temp目录,导致探针写缓存文件失败。
解决方法:
在Tomcat根目录下创建temp目录后重启应用。
- 问题现象2:
只有tingyun_starter.log日志生成,但是日志中无报错信息。
解决方法:
检查tingyun.properties所有更改过的配置项,更改内容不应有缺失/冗余或者字符串后面不应有多余的空格。
- 问题现象3:
tingyun_agent.log和tingyun_starter.log均生成,查看tingyun_agent.log日志,具体报错信息如下:
原因:
探针与collector之间网络通信失败,无法连接到collector。
解决方法:
检查探针与collector之间的网络通信状况,保证两台机器之间的网络及端口通信正常。
- 问题现象4:
License_Key填写错误,导致探针注册失败。
解决方法:
校正License_key,可从“账户管理”中查看到具体的License_Key。
- 问题现象5:
探针为root权限,但是tomcat为非root权限,使用非root权限启动tomcat时,探针未启动,没有生成logs文件夹。
解决方法:
将tingyun目录更改为tomcat启动用户。
- 问题现象6:
应用加载探针后,tingyun目录下未生成logs文件夹。
原因:
环境中存在友商探针。
解决方法:
卸载掉友商探针。
探针部署后不采集数据怎么办?
1、查看探针日志。
确定探针日志是否有异常,init是否成功,init成功有如下日志:
Tingyun Agent enabled for: testl.
说明:testl是应用名称。
2、确认应用的框架是否在探针支持列表内。
支持范围请参见探针支持列表。
3、确认探针是否处于熔断状态。判断方法请参见如何判断探针是否熔断。
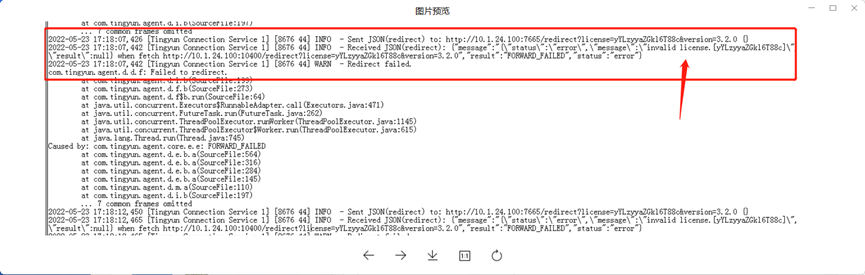
常见的报错
1、部署Java探针时出现如下图报错,说明是license填写错误,需要重新检查并输入。
2、Java探针日志报如下错误,说明是session过期了,需要重启一下Agent Collector。

如何检测探针和Agent Collector之间通信是否正常?
1、通过Ping确认网络是否正常
通信正常则如图下:
通信异常则如图下,需要调整网络策略或将collector部署到网络通信正常的机器上。
2、通过telnet确认端口通信正常
通信正常则如图下:
通信异常则如图下,需要开放端口、调整防火墙策略或检查collector进程是否启动成功。
如何判断探针是否熔断?
1、首先确认探针熔断开关是否开启。
确认方法:查看Received JSON(init)或Received JSON(getCmd)中resource_breaker--> enabled 的值,true表示开启探针熔断,false表示关闭探针熔断。
"resource_breaker": {
"sample_memory": 70, ---采样内存阈值
"disable_memory": 80, ---禁用内存阈值
"sample_gcCPUTime": 15,---采样gcCPU时间阈值(仅对Java探针生效)
"sample_rate": 0, ---目前Java Agent 是动态采样,该值不生效
"disable_gcCPUTime": 20,---禁用gcCPU时间阈值(仅对Java探针生效)
"enabled": true, ----true:启用探针熔断;false:关闭探针熔断
"sample_cpu": 80, ---对非Java探针生效
"disable_cpu": 90 ---对非Java探针生效
}
2、当开启探针熔断时,通过以下两种方式判断探针是否熔断。
resource metric is : ResourceMetric{percentageUsedMemory=6.31876000620646, gcCpuTimePercentage=0.0, sampleMemory=10, sampleGcCpuTime=10, disableMemory=5, disableGcCpuTime=20, sampleLoad=-1.0, disableLoad=-1.0, systemCpuLoad=-1.0, state=DEFICIENT}
ResourceBreaker state : DISABLED , DummyAction SampleRate : 100 , NormalAction SampleRate : 0 , SampleAction SampleRate : 0
state:通过该关键词的值判定探针是否熔断。共有三种取值:
- RICH:资源充足,此时探针处于全量采集状态。
- TOLERABLE:资源可容忍,此时探针处于采样状态。
- IFICIENT:资源匮乏,此时探针处于熔断状态。
Sample Rate:通过采样率判定。
NormalAction Sample Rate:采样率(100:全量采集;0:全都不采)。
DummyAction Sample Rate:不采率(100:全都不采;0:全量采集)。
为什么启用MQ消费端监控后,3.6.7及以上版本依然没有采集Kafka跨应用追踪?
以下情况在开启MQ消费端监控时会导致Kafka生产或消费消息失败,所以3.6.7及以上版本新增Kafka追踪监控开关,默认禁用Kafka追踪监控:
- 应用使用的Kafka集群版本为 0.7.0 ~ 0.10.x,并且生产者的Kafka Client版本为 0.11.0.0 + ,在应用生产消息时报错,报错信息为:
Magic v1 does not support record headers。 - 应用使用的Kafka集群版本为 0.11.0.0 ~ 1.0.1、1.1.0 ,且生产者的Kafka Client版本为 0.11.0.0 +,且消费者的Kafka Client版本为 0.8.x ~ 0.10.x ,在消费者消费消息时,Kafka集群报错且消费失败,造成消息积压。Kafka集群报错信息为:
Magic v1 does not support record headers。
如果确认应用不存在以上场景,可以同时开启MQ消费端监控和Kafka追踪监控。否则只能关闭MQ消费端监控和Kafka追踪监控,或只开启MQ消费端监控。
当Dubbo应用部署探针后,如果Dubbo请求报错:The attachments of RpcContext must not contain \',\' or \'=\' when using rest protocol,怎么解决?
由于应用A使用Dubbo协议调用应用B时,若应用A安装探针,则应用A会将跨应用所需的TingyunId写入Dubbo的Attachments中,若应用B不安装探针,则会透传应用A的TingyunId,而应用B使用Rest协议调用应用C时,会校验Attachments(不允许有,和=), TingyunId里包含,和=,从而探针导致应用报错。临时规避建议如下:
若部署的探针版本为 3.3.0 ~ 3.6.7.2,建议采取以下方案:
在 tingyun.properties 中增加如下配置,禁用 Dubbo 插件,并重启应用。配置如下:
class_transformer.tingyun-apache-dubbo-plugin-2.0.enabled=false class_transformer.tingyun-apache-dubbo-plugin-2.7.0.enabled=false class_transformer.tingyun-apache-dubbo-plugin-2.7.3.enabled=false class_transformer.tingyun-apache-dubbo-plugin-2.7.5.enabled=false class_transformer.tingyun-apache-dubbo-plugin-2.7.6.enabled=false class_transformer.tingyun-apache-dubbo-triple-plugin-3.0.enabled=false采取以上规避方案,则探针无法采集Dubbo相关数据,具体来说,无法采集Dubbo跨应用和Dubbo服务端的事务数据。