诊断应用卡顿问题
网站或App卡顿、页面加载过慢是互联网应用最常见的问题之一。针对这类问题,基调听云应用与微服务提供线程剖析、事务追踪、错误分析、数据库分析、NoSQL分析等一系列诊断手段,帮助您快速准确定位应用中的性能问题和错误,进而解决应用卡顿问题。
问题分析
定位应用卡顿问题的原因是一个比较复杂的系统工程。原因如下:
请求的调用链路长
- 从前端页面到Web应用服务器、后台应用、下游应用、数据库、MQ、NoSQL,任何一个环节出现问题都有可能导致应用卡顿。
- 如果应用采用了微服务架构,调用链路会更加复杂,而且不同组件可能由不同的团队和人员维护,加大了问题排查的难度。
日志不全
追踪应用日志是排查应用问题的主要方法,但出现问题的位置往往无法预期,而且应用响应慢或卡顿通常是偶发现象,要找到慢的原因,需要为每次调用在每个可能出现问题的地方打印日志,这样成本会非常高。
代码监控不足
由于应用快速的迭代,导致应用频繁修改接口等情况,代码的质量无法得到保证。这种情况下,需要一个强大的监控系统来自动监控应用的每一个接口,自动记录有性能问题的接口调用。
前提条件
在诊断具体的应用卡顿原因前,请确保已经为应用部署了基调听云应用与微服务探针。
诊断步骤
请您通过以下步骤进行诊断:
登录应用与微服务控制台。
在左侧导航栏中选择应用,然后在页面左上角的业务系统下拉菜单中选择应用所属的业务系统,在右上角选择发生卡顿的时间段。
在应用列表中找到发生卡顿的应用,点击查看健康度是否变成警戒或者严重状态,平均响应时间、错误率是否过高,Apdex是否过低。
如果存在上述异常,点击卡顿应用的名称,进入应用详情页面。

从拓扑图中可以看到该应用在调用其他应用、MQ、数据库或者NoSQL的连线是否变黄或者变红。此时已大致能判断哪个部分出了问题。如果没有变黄或变红,请继续下一步。
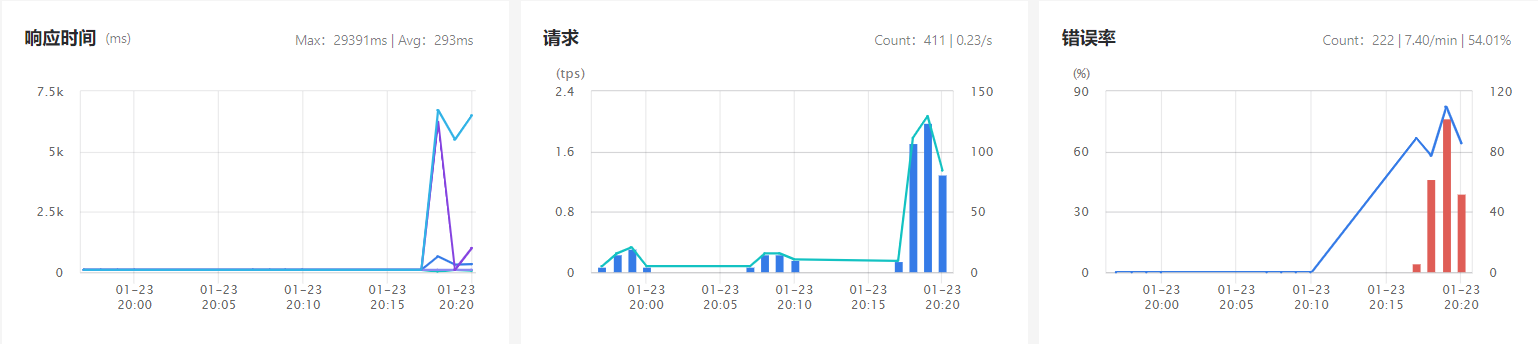
继续看下面的三个图表,主要看吞吐率和错误率是否有大的变化。
一般来说,应用的错误率、吞吐率等指标会保持平稳的状态,如果突然升高,可能有以下原因:
对功能进行了迭代升级,导致错误率升高。
应用实例掉线了,导致吞吐率升高,由于应用负载有限,导致应用响应时间变长。
搞活动、促销、或应用的使用高峰时段,吞吐率的增加会导致应用超负荷,应用响应时间变长。
- 内存溢出,应用响应时间变长。
- ……
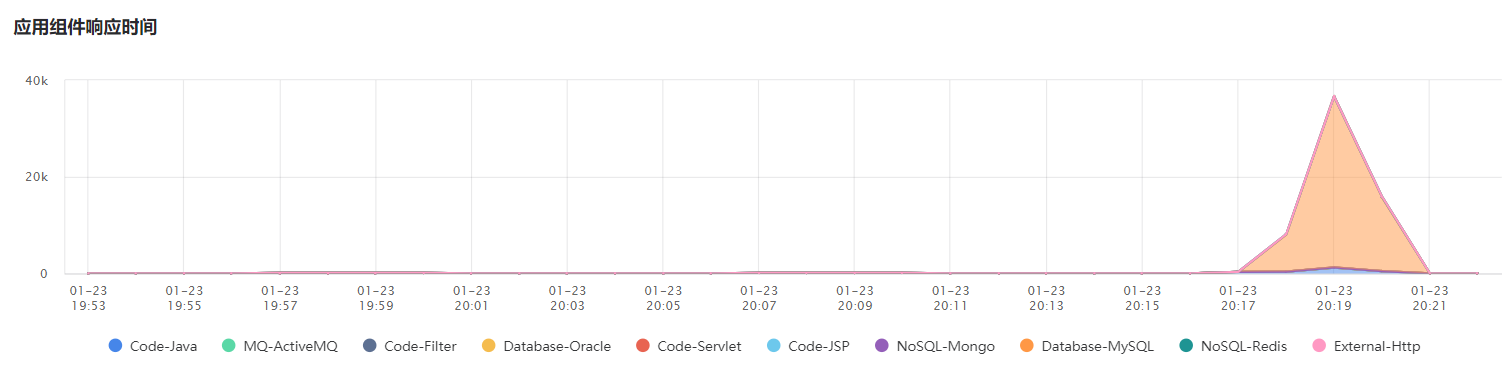
再看最下面的应用组件响应时间堆叠图,这个图展示的是应用中所有事务的响应时间的构成部分分别所占用的时间。构成部分包含代码执行时间、各类数据库访问时间、各类NoSQL访问时间、各类MQ访问时间、各类外部服务响应时间。我们能够清楚的看到具体是哪部分发生了变化,从而更加确认对拓扑图的判断。
接下来我们分别从常用的错误分析和组件分析两个思路来分析问题。
错误分析
如果错误率明显地上升,可按以下步骤进行错误分析。
在页面顶部单击错误页签,进入该应用的错误统计分析页面。页面下方的事务错误列表会列出应用发生的所有错误,默认按发生次数从高到低排序。

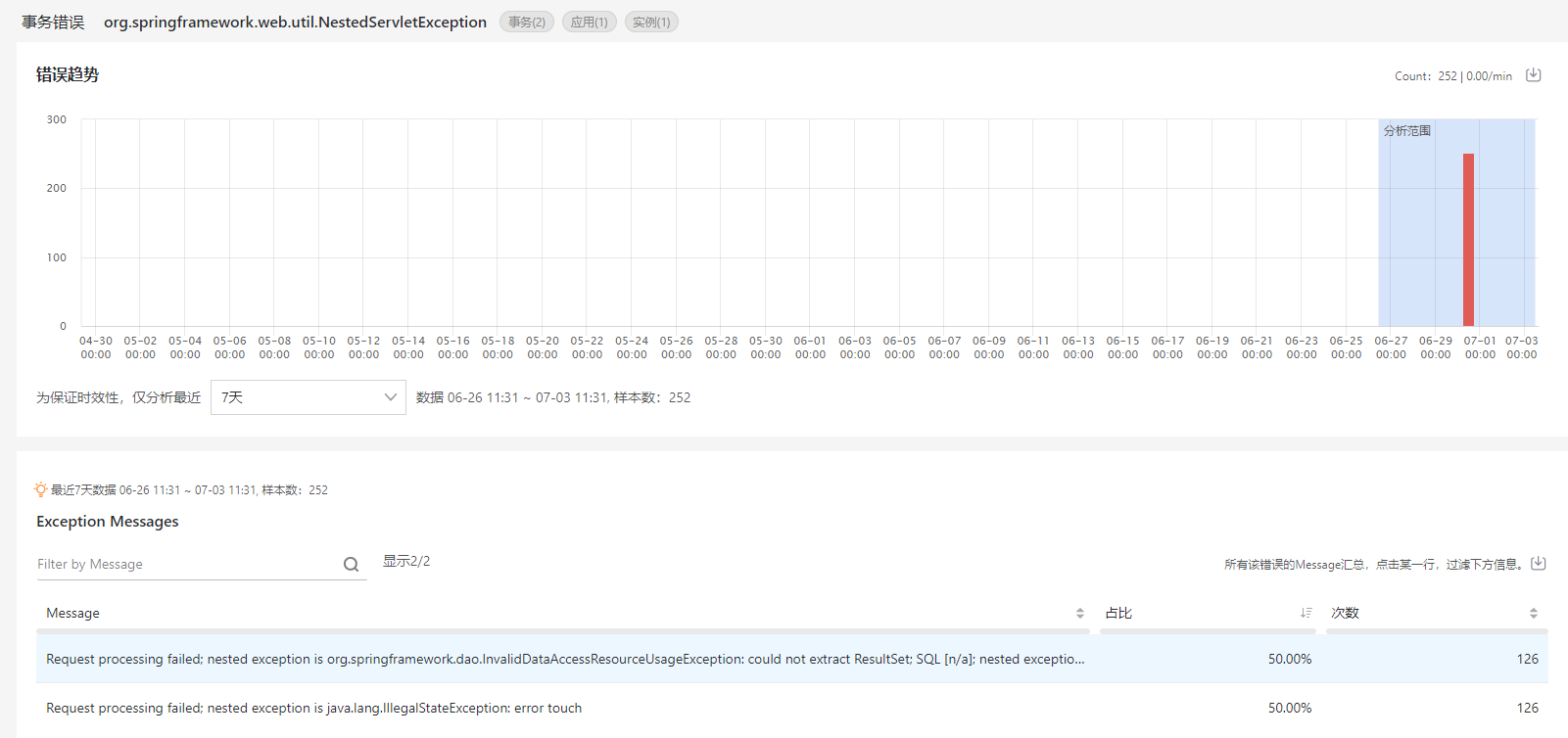
单击发生次数最多的错误名称,追踪这个错误的详情。
问题发生时,往往查看靠近问题发生时间点前附近时间的数据,才能相对高效的、有针对性的定位导致错误的问题。您可以在错误趋势图的下方下拉菜单中,选择当前时间点之前时间范围的数据进行分析,分析结果体现在下方的Exception Messages、Stacktrace、Root cause、异常追踪、Referring pages、Client IPs和Caller Applications中。同一个错误的报错信息会有很多,错误发生的原因也可能千差万别,具体分析过程可参见错误详情分析。
分析至此,如果您已发现了应用卡顿的原因,可以进行下一步的代码优化工作。
组件分析
如果已判定是某个组件出了问题,则可按照以下步骤进行诊断,以数据库组件为例。
在左侧导航栏中选择服务组件>Database组件,然后在页面左上角的业务系统下拉菜单中选择数据库所属的业务系统,在右上角选择发生卡顿的时间段。
数据库实例列表按平均执行时间从高到低进行排序。单击执行时间最长的数据库实例名称,进入数据库概览页面。
在上方单击响应时间页签,进一步分析数据库的性能问题。
- 平均响应时间&吞吐率图表可以查看响应时间和吞吐率是否有波动。
- 调用者分析部分展示所有调用该数据库实例的事务的性能详情。对列表按SQL响应时间从高到低排序,能看出哪些事务调用SQL语句时有性能问题。如果同时这个事务的调用占比很高,那么基本能断定是这个事务调用的SQL语句需要优化。注意,调用者(服务接口)列如果有值,说明是事务下游的服务接口调用的数据库实例。
- 选择问题事务,下方的追踪列表部分可以查看由于调用该数据库实例而发生的事务追踪。对列表按SQL响应时间从高到低排序,单击事务的名称继续追踪具体的SQL语句。
在事务追踪详情页面下方选择SQL分析页签,从平均执行时间列即可排查出需要优化的SQL语句了。

在事务追踪详情页面下方选择调用栈页签,单击下图红框中的数据库图标可以找到慢SQL,继续单击
 图标可定位发生调用的代码位置。
图标可定位发生调用的代码位置。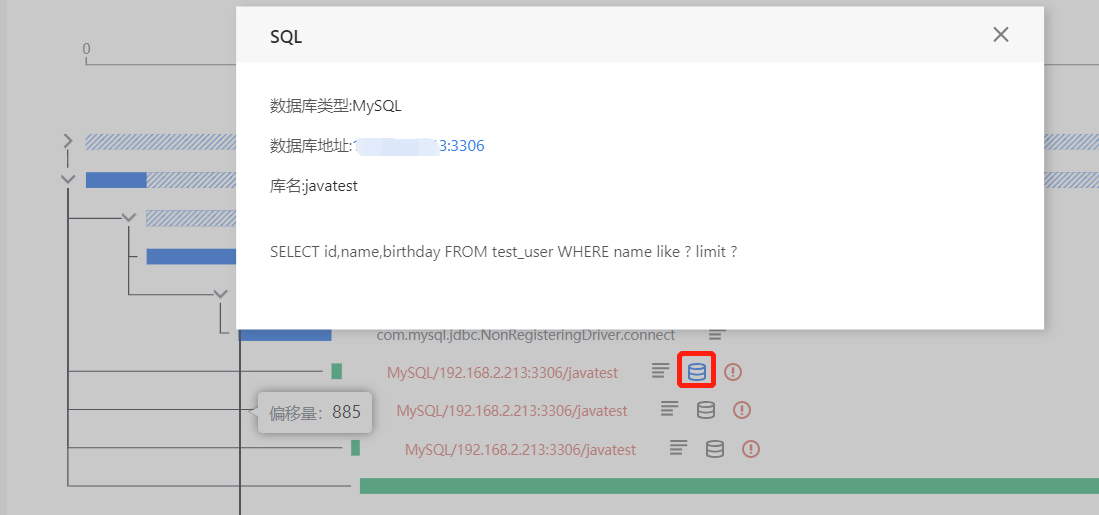
有些情况下会因为数据库(包含NoSQL)连接池资源紧张,导致事务响应时间变长。在代码堆栈中会展示数据库连接池的性能数据。将鼠标悬浮在连接池名称上,可查看总时间(独占时间+其他调用的时间)、独占时间(该代码段自身的执行时间)、独占时间占比和偏移量(该代码段相对事务起始时间点的时间偏移量)。如果发现独占时间较长,可单击连接池图标
 ,可查看所对应的连接池的详细指标进行分析。
,可查看所对应的连接池的详细指标进行分析。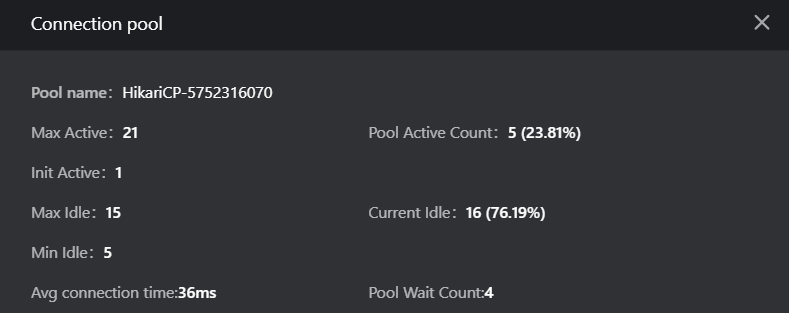
其他组件的分析与数据库分析类似,您可以按照上述思路进行诊断。分析完成后,您会发现应用卡顿的原因,这将有效地帮助您进行下一步的代码优化工作。